
# 引言
# 适用范围
本文档适用于集成主数据管理平台的三方应用系统(供开发者参考),文档的适用产品版本为:7.3.0。
# 编写目的
本文档主要介绍主数据管理平台提供的服务接口以及调用方式。
# 适用读者
本文档的适用读者范围主要是应用系统接入主数据管理平台过程中的设计和开发人员。
# 服务接口说明
- 在线 swagger 文档参考
http://<ip>:<port>/swagger-ui.html - 统一使用RESTFul + JSON格式
- 业务表API调用认证统一使用客户端凭证
# 获取客户端凭证
# 生成客户端
登入账号之后,进入菜单管理门户/数据分发/客户端管理,新增客户端。
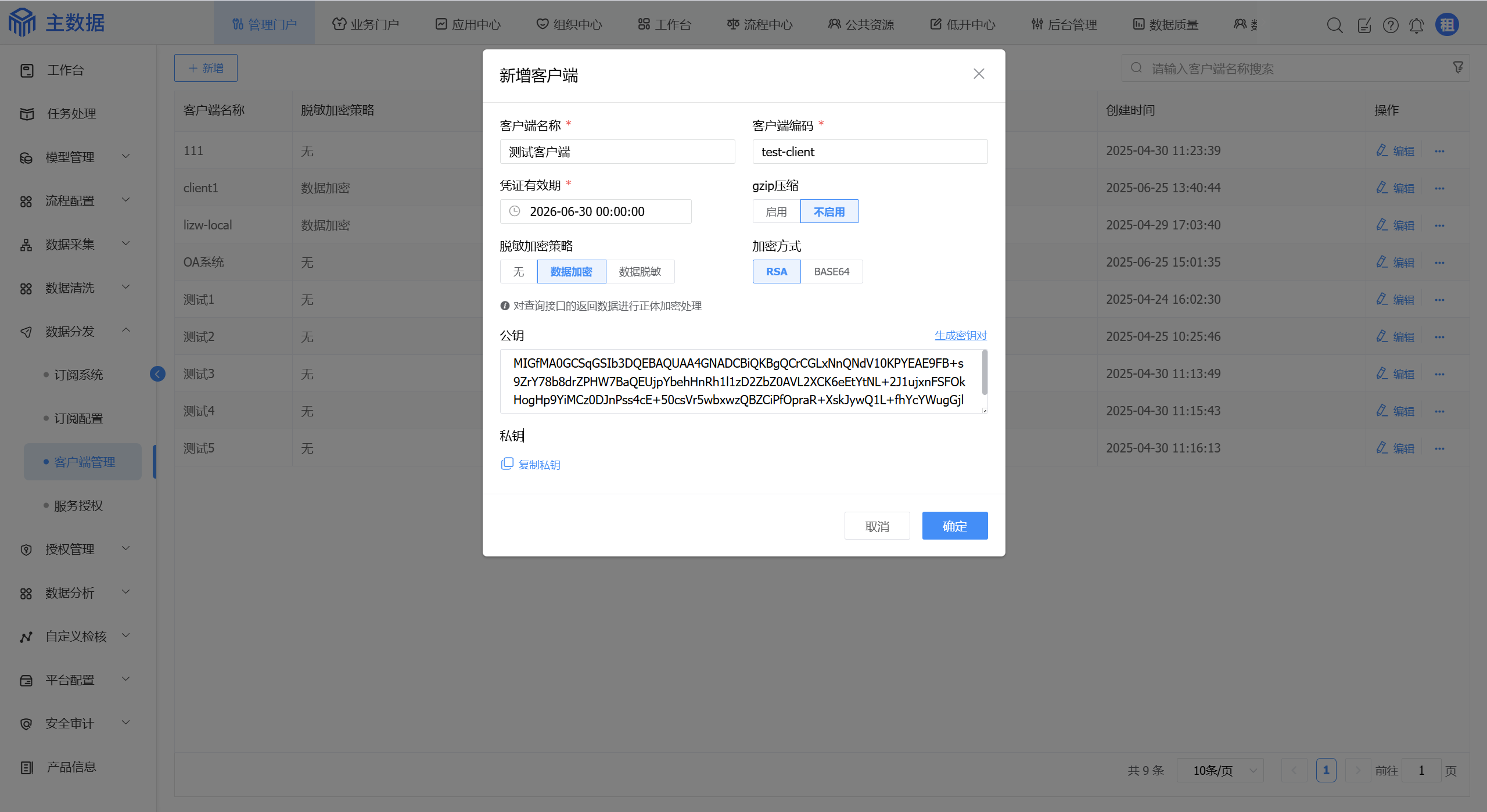
点击确定按钮后:
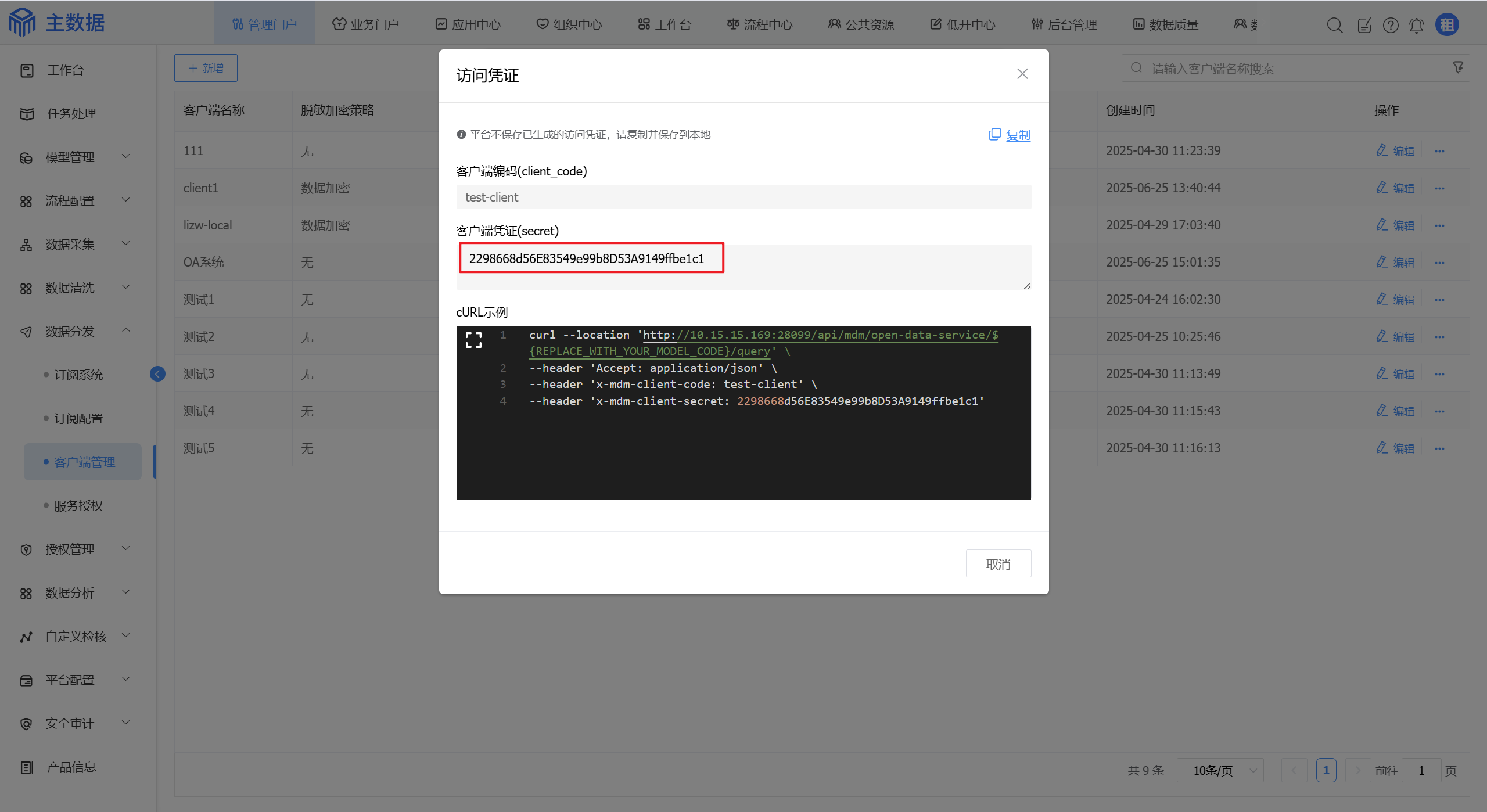
平台不保存客户端凭证,请复制后保存到本地,后面调用主数据的API时会用到。
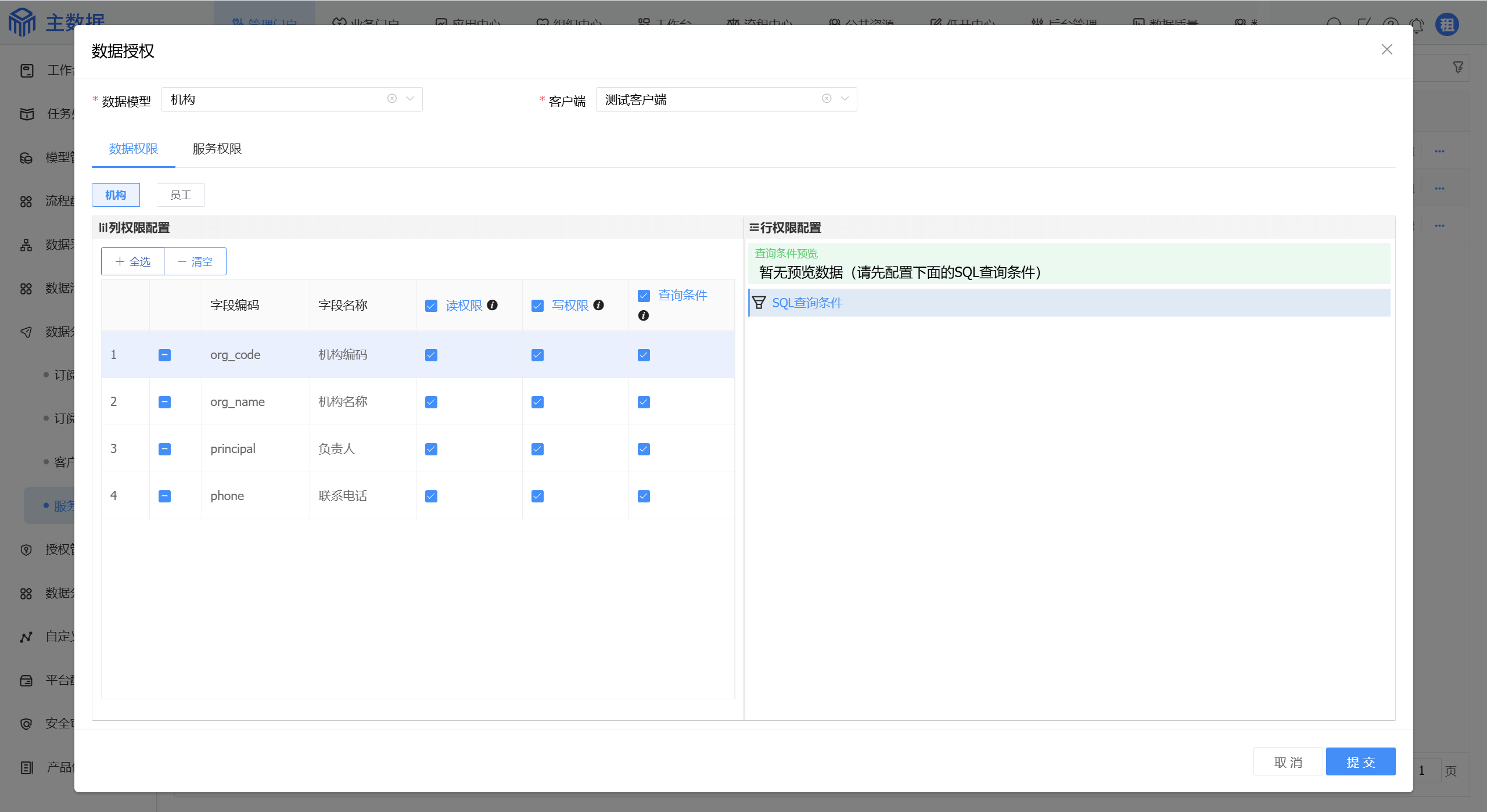
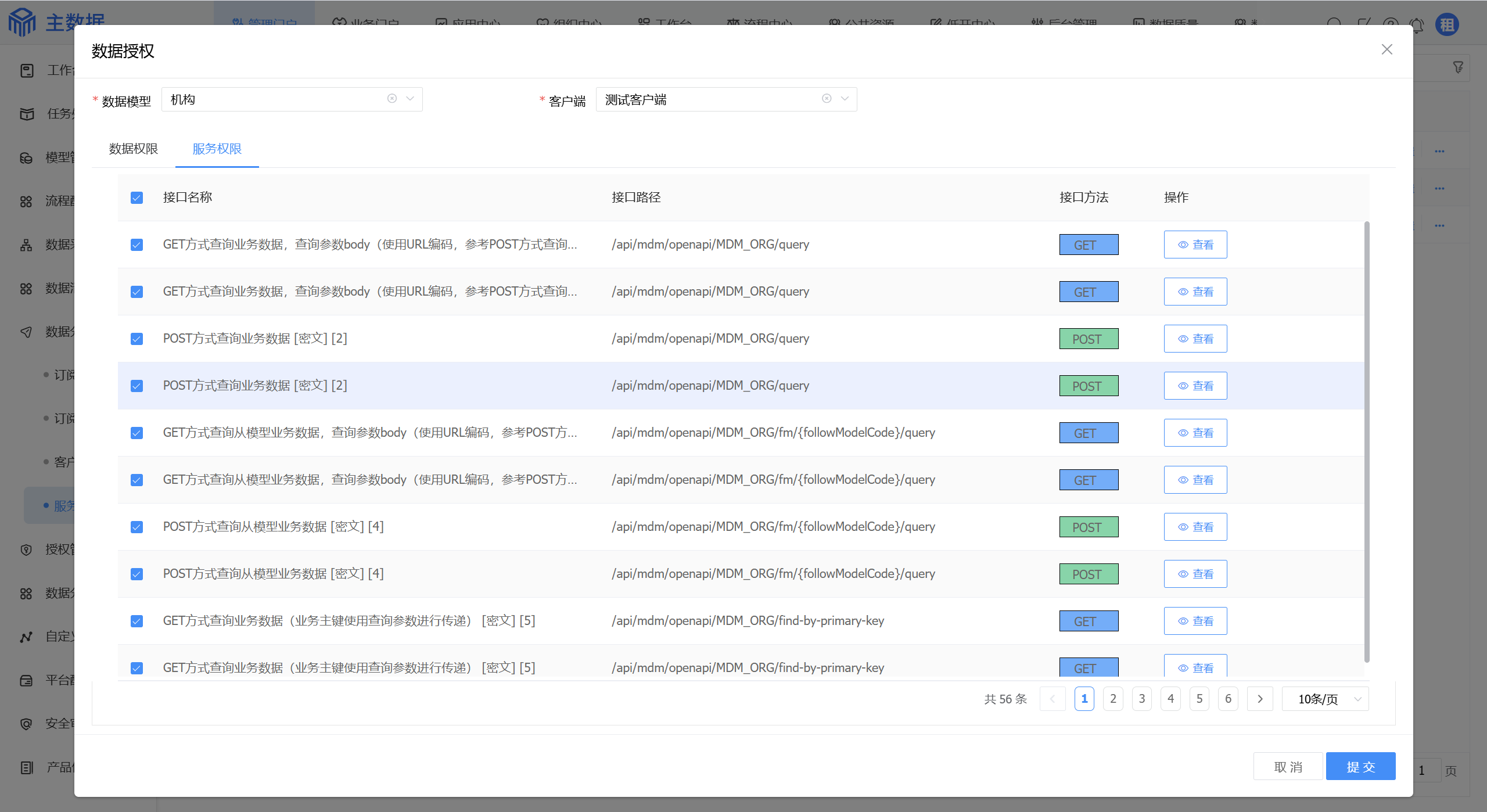
# 服务授权
进入菜单管理门户/数据分发/服务授权,添加授权。
选择需要授权的数据模型和上面生成的客户端,配置数据权限和服务权限:
# 使用凭证
在调用主数据的业务表API时,每次请求必须携带客户端编码和凭证,需要在请求的头中增加下列参数(或者使用Basic Authorization方式在请求头中传递凭证):
| 参数 | 位置 | 类型 | 示例 |
|---|---|---|---|
| Accept | Header | String | application/json |
| x-mdm-client-code | Header | String | test-client |
| x-mdm-client-secret | Header | String | 2298668d56E83549e99b8D53A9149ffbe1c1 |
注意:在MDM管理门户,
数据分发/客户端管理下新建的客户端并生成访问凭证,注意其设置的凭证有效期,到期后可以重新生成。
# 业务表APIs
# 查询业务数据(GET) [1]
- 方法(Method):
GET - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/query - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| withSysColumn | Path | Boolean | 查询结果是否包含系统字段 |
| pageIndex | Query | Integer | 分页页数 |
| pageSize | Query | Integer | 分页大小 |
| body | Query | String | 查询参数 |
GET方式查询就是把POST方式的请求Body进行URI编码后转成查询参数(body)方式传递。
响应报文示例:
# 查询业务数据(POST) [2]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/query - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| withSysColumn | Query | Boolean | 查询结果是否包含系统字段 |
| pageIndex | Query | Integer | 分页页数 |
| pageSize | Query | Integer | 分页大小 |
| param | Body | MDMQueryParam | 查询参数 |
- 请求报文体结构:(报文体的所有参数都是可选参数|报文结构同样适用于查询从(子)模型业务数据)
{
// 查询条件args逻辑关系,若为false则逻辑关系为or。默认为true,即逻辑关系为and
"and": true, // Optional
// 查询条件,可配置多个条件。默认为空
"args": [ // Optional
{
"matchValue": "value1",
"name": "field1" // 缺省匹配方式`eq`
}
],
// 需要返回的字段,默认返回调用者拥有所有权限的字段,可能含有系统字段(withSysColumn=true)
"fields": [ // Optional
"field1", "field2", "field3", "field2", "..."
],
// 引用字段选项配置
"dictRef": { // Optional
"enabled": true, // 启用引用字典字段数据预处理
"replace": false, // 使用其关联字典项显示名称替换值
"suffix": "__ref", // 当禁用替换模式情况下,追加其关联字典项显示名称到每条数据中 e.g { "gender": "F", "gender__ref": "女" } | e.g. {"course": "Math,English", "course__ref": "数学,英语"}
"full": true // e.g {"gender": "F", "__genderObject": {"code": "F", "name": "女", "remark": "性别"}} | e.g. {"course": "Math,English", "__courseObject": [{"code": "Math", "name": "数学", "remark": "课程"}, {"code": "English", "name": "英语", "remark": "课程"}]}
},
"modelRef": { // Optional
"enabled": true, // 启用引用模型字段数据预处理
"replace": false, // 使用其关联模型业务数据显示名称替换值
"suffix": "__ref", // 当禁用替换模式情况下,追加其关联模型业务数据显示名称到每条数据中 e.g { "class": "250101", "class__ref": "25届数学专业1班" } | e.g. {"course": "Math,English", "course__ref": "数学,英语"}
"full": true // e.g {"gender": "F", "__genderObject": {"code": "F", "name": "女", "remark": "性别"}} | e.g. {"course": "Math,English", "gender": [{"code": "Math", "name": "数学", "remark": "课程"}, {"code": "English", "name": "英语", "remark": "课程"}]}
},
"fieldRef": { // Optional, 优先级高于dictRef和modelRef(这俩算是全局默认设置。即应用于所有自定义格式化输出的引用字段),本配置允许为每个引用字段定制格式化输出
"gender": { // 主模型自身的字段
"enabled": true // e.g. {..., "gender": "M" } -> {..., "gender": "M", "gender__ref": "男" }
},
"family.gender": { // 内部从模型的字段(使用英文点连接从模型编码和其字段编码)
"enabled": true
},
"family.relationship": { // 内部从模型的字段(使用英文点连接从模型编码和其字段编码)
"enabled": true,
"replace": true // e.g. { ..., "relationship": "FATHER" } -> { ..., "relationship": "父亲" }
}
}
"fetchFMD": { "enabled:" false }, // 加载从模型数据 e.g. 简历模型业务数据(从模型work_exp:工作经历) [{"no": "1", "name": "张无忌", "work_exp": [{...}]}] | 支持设置只加载其中某些从模型以及每个从模型的部分字段
// 复杂查询条件,详见下文的>>补充说明
"criteria": { // Optional(简单过滤逻辑可以使用#args,否则可以使用criteria进行复杂过滤逻辑嵌套)
"matchType": "or",
"children": [
{
"name": "gender",
"matchValue": "女",
"matchType": "eq"
},
{
"name": "native",
"matchValue": "130300",
"matchType": "eq"
}
]
},
// 默认不排序,按照用户指定的字段进行排序
"sorts": [
{
"asc": true,
"name": "field1"
},
{
"asc": false,
"name": "field1"
}
],
// 结果列是否数据脱敏,默认为false,不进行数据脱敏处理
"desensitization": false
}
- 请求报文体参考示例:
{
"args": [
{
"name": "M_DATA_STATE",
"matchValues": [
"0"
],
"matchType": "in"
},
{
"name": "id",
"matchValue": "000",
"matchType": "starts_with"
},
{
"name": "age",
"matchValue": "7",
"matchType": "lt"
}
],
"criteria": {
"matchType": "or",
"children": [
{
"name": "gender",
"matchValue": "女",
"matchType": "eq"
},
{
"name": "native",
"matchValue": "130300",
"matchType": "eq"
}
]
},
"sorts": [
{
"name": "id",
"asc": false
}
],
"desensitization": true
}
- 响应报文体示例:
{
"content": [
{
"M_ID": "f851441c-f0fa-49f7-92fb-97c0436d8b7c",
"M_DATA_UID": "c1ab257e-fb42-4086-955b-cb3f779acf53",
"M_DATA_VERSION": 1,
"M_DATA_STATE": 0,
"M_DATA_FROM": "mdm::manual",
"M_SECURITY_LEVEL": 4,
"M_CREATED_AT": "2025-06-25 10:37:15",
"M_CREATED_BY": "admin",
"M_LAST_MODIFIED_AT": "2025-06-25 10:37:15",
"M_LAST_MODIFIED_BY": "admin",
"org_code": "shanghai",
"org_name": "上海总公司",
"principal": "张三"
}
],
"pageable": {
"sort": {
"unsorted": true,
"sorted": false,
"empty": true
},
"pageNumber": 0,
"pageSize": 10,
"offset": 0,
"unpaged": false,
"paged": true
},
"last": true,
"totalElements": 1,
"totalPages": 1,
"sort": {
"unsorted": true,
"sorted": false,
"empty": true
},
"first": true,
"numberOfElements": 1,
"size": 10,
"number": 0,
"empty": false
}
注:以"M_"开头的字段为主数据管理平台的系统字段。
# 查询条件匹配类型
- 单一值:
eq, ne, gt, ge, lt, le,使用matchValue存放值,所有可查询的字段均使用String类型存放 - 模糊匹配:
like, not_like,matchOption缺省值contains,matchValue存放模糊匹配关键字,可选值:contains | starts-with | ends-with - 模糊匹配:
starts_with,contains,ends_with,not_starts_with,not_contains,not_ends_with(MDM7.3.0版本新增匹配方式以简化传参) - 值域范围:
between, not_between,适用于日期、时间、数值类型,matchValues存放2个字符串值且后者大于前者 - 枚举值:
in, not_in - 空/非空:
is_null, not_null - 其他:缺省类型值为
eq,对于日期建议使用Long型表示 、支持这些格式{number}d, {number}h, {number}m, {number}s, {number}, {yyyy-MM-dd}, {yyyy-MM-dd HH:mm:ss}
# 数据状态
- 0:生效(有效)
- 1:停用(禁用)
- 2:作废(废弃)
- 3:生效待审批(复合状态|实际状态为编辑)
- 4:历史
- 5:编辑
- 6:启用待审核(复合状态|实际状态为停用)
- 7:停用待审核(复合状态|实际状态为生效)
- 8:作废待审核(复合状态|实际状态为生效)
# 数据状态的匹配方式
使用等于(eq)进行匹配,如:
{
"name": "M_DATA_STATE",
"matchValue": "0"
}
使用不等于(ne)进行匹配,如:
{
"matchType": "ne",
"matchValue": "0",
"name": "M_DATA_STATE"
}
使用在枚举值内(in)进行匹配,如:
{
"matchType": "in",
"matchValues": [ "0", "1", "2" ],
"name": "M_DATA_STATE"
}
使用不在枚举值内(notin)进行匹配,如:
{
"matchType": "notin",
"matchValues": [ "0", "3", "5" ],
"name": "M_DATA_STATE"
}
# 其他查询参数
withSysColumn
查询结果包含业务数据系统字段数据信息(数据版本/数据状态/更新时间等)。execCountSql
`execCountSql=false`, 一般情况下在查询条件不变的条件下,第`n + 1`次查询时可以不需要后端返回记录总数,可以传递此参数节省一次SQL查询(节约一点点时间) 或是在使用如字段主键之类的条件查询,结果集是可预期内的数据。此参数不影响数据查询结果。非法参数处理策略
查询条件非法参数处理策略,默认忽略(`IGNORE`)可以传递查询参数修改为 `illegalArgStrategy=ERROR`分类模型:限制子模型(继承模型|常见于如物料类模型)范围进行大类检索
1)指定分类:`classifyDirId={分类代码}` 2)限制模型:`inheritedModels={模型编码1},{模型编码2},...`
# 补充说明
MDM后端服务拼装转化后的SQL条件格式:
WHERE ( 1.行权限SQL条件 ) AND ( 2.系统字段参数#args ) AND ( 3.用户查询条件#args ) AND ( 4.复杂嵌套查询条件#criteria ) AND ( 5.模型额外条件 )
1. 支持复杂的嵌套结构,在模型管理角色授权界面上进行配置;
2. 系统内置字段,模型的数据维护界面上的数据状态查询框即系统字段 `M_DATA_STATE`
3. 用户查询条件#args,根据用户需要,使用模型的合法字段作为查询条件,多条件之间的逻辑关系默认AND,支持传参设置为OR;
4. 复杂嵌套查询条件#criteria,可与args混用;
5. 模型扩展条件,目前只有继承模型会额外传递可选查询参数(二选一),`includeDescendants=true` 查询包括子孙模型的数据,`includeChildren=true` 查询包括子模型的数据,MDM后端转化并拼装后的SQL为 `M_MODEL_ID = ?` 或 `M_MODEL_ID in (?, ?, ?, ...)`
- 简单查询条件可以使用
args参数搜索,默认逻辑为and。 - 若需要实现复杂查询条件,则使用
criteria参数,其可选配置属性如下:
"criteria": {
"matchType": "and",
"children": [{
"name": "city",
"matchValues": ["beijing", "shanghai"],
"matchType": "not_in"
}, {
"name": "name",
"matchValue": "科技大学",
"matchType": "ends_with"
}, {
"matchType": "or",
"children": [{
"name": "tags",
"matchValues": ["211", "985"],
"matchType": "in"
}, {
// ...
}]
}]
}
criteria可以与args参数同时使用,其连接逻辑为and。
where A=a and (B=b or C=c or D=d)
一个括号对应一个children嵌套条件,与该children同级的matchType必须是and或or,该匹配方式为children内层通用逻辑,上述查询的参数结构示意如下:
"criteria":{
"matchType":"and",
"children":[
{A=a},
{
"matchType":"or"
"children":[
{B=b},
{C=c},
{D=d}
]
}
]
}
其中B=b与C=c与D=d之间的运算逻辑为or,当其中任意一个条件成立时,该查询条件结果为真。
此外,可以在数据授权页通过行权限配置预设查询条件。
# 查询参数示例
有以下数据:
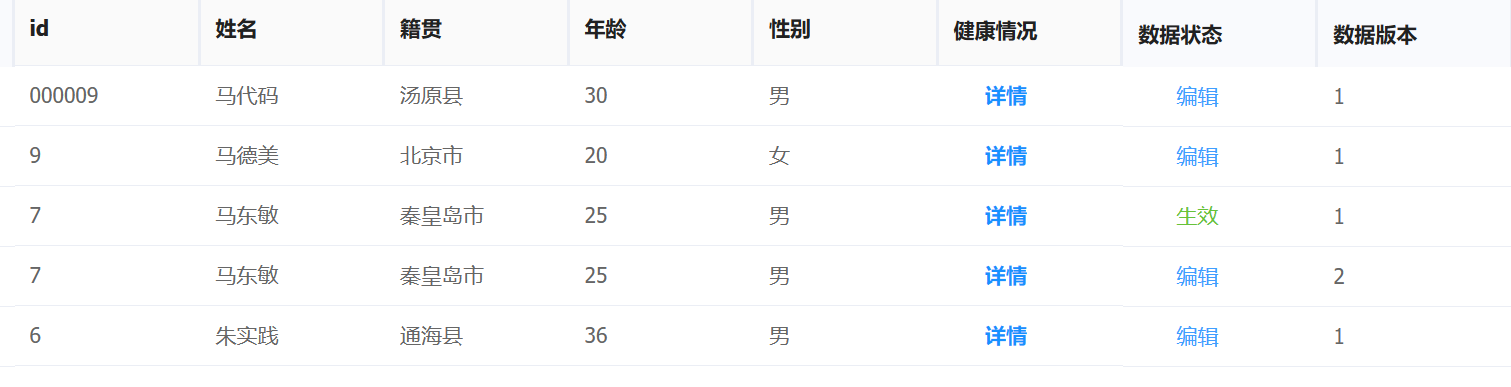
如果需要查询编辑或生效状态,姓名中包含“马”,性别为“女”或籍贯为“秦皇岛市”的数据,查询参数如下:
{
"args": [
{
"name": "M_DATA_STATE",
"matchValues": [
"0",
"5"
],
"matchType": "in"
},
{
"name": "name",
"matchValue": "马",
"matchType": "contains"
}
],
"sorts": [],
"criteria": {
"matchType": "or",
"children": [
{
"name": "gender",
"matchValue": "女",
"matchType": "eq"
},
{
"name": "native",
"matchValue": "130300"
}
]
},
"and": true,
"desensitization": true
}
将返回3条数据,分别是生效状态id为7的数据、编辑状态id为7的数据和编辑状态id为9的数据。
如果要查询编辑状态的,姓名中包含“马”字,性别为女,或性别为男且籍贯为“汤原县”或年龄为25或28,的数据,查询参数如下:
{
"args": [
{
"name": "M_DATA_STATE",
"matchValues": [
"5"
],
"matchType": "in"
},
{
"name": "name",
"matchValue": "马",
"matchType": "contains"
}
],
"sorts": [],
"criteria": {
"matchType": "or",
"children": [
{
"name": "gender",
"matchValue": "女",
"matchType": "eq"
},
{
"children": [
{
"name": "gender",
"matchValue": "男",
"matchType": "eq"
},
{
"children": [
{
"name": "native",
"matchValue": "230828",
"matchType": "eq"
},
{
"name": "age",
"matchValue": [ "28", "25" ],
"matchType": "in"
}
],
"matchType": "or"
}
],
"matchType": "and"
}
]
},
"and": true,
"desensitization": true
}
将返回3条数据,分别是编辑状态id为7的数据、编辑状态id为000009的数据和编辑状态id为9的数据。
# 查询从(子)模型业务数据(GET) [3]
- 方法(Method):
GET - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/fm/{followModelCode}/query - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 主模型编码 |
| followModelCode | Path | String | 从(子)模型编码 |
| withSysColumn | Query | Boolean | 查询结果是否包含系统字段 |
| pageIndex | Query | Integer | 分页页数 |
| pageSize | Query | Integer | 分页大小 |
| body | Path | String | 查询参数 |
GET方式查询就是把POST方式的请求Body进行URI编码后转成查询参数(body)方式传递。
响应报文示例:
# 查询从(子)模型业务数据(POST) [4]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/fm/{followModelCode}/query - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 主模型编码 |
| followModelCode | Path | String | 从(子)模型编码 |
| withSysColumn | Query | Boolean | 查询结果是否包含系统字段 |
| pageIndex | Query | Integer | 分页页数 |
| pageSize | Query | Integer | 分页大小 |
| param | Body | MDMQueryParam | 查询参数 |
请求报文体参考示例:
与前面查询其主模型业务数据接口参数类似(参考查询业务数据(POST) [2])
响应报文示例:
{
"content": [
{
"M_ID": "dc5945d3-7cfb-40aa-9d89-bb0cced619b7",
"M_FK_DATA_ID": "f851441c-f0fa-49f7-92fb-97c0436d8b7c",
"M_FK_DATA_UID": "c1ab257e-fb42-4086-955b-cb3f779acf53",
"M_ORDER_VALUE": 1,
"emp_code": "lisi",
"emp_name": "李四",
"position": "研发",
"email": "lisi@primeton.com",
"_main_": { // 主模型信息
"M_ID": "f851441c-f0fa-49f7-92fb-97c0436d8b7c",
"M_DATA_UID": "c1ab257e-fb42-4086-955b-cb3f779acf53",
"M_DATA_VERSION": 1,
"M_DATA_STATE": 0,
"M_DATA_FROM": "mdm::manual",
"M_SECURITY_LEVEL": 4,
"M_CREATED_AT": "2025-06-25 10:37:15",
"M_CREATED_BY": "admin",
"M_LAST_MODIFIED_AT": "2025-06-25 10:37:15",
"M_LAST_MODIFIED_BY": "admin",
"org_code": "shanghai",
"org_name": "上海总公司",
"principal": "张三"
}
}
],
"pageable": {
"sort": {
"unsorted": true,
"sorted": false,
"empty": true
},
"pageNumber": 0,
"pageSize": 10,
"offset": 0,
"unpaged": false,
"paged": true
},
"last": true,
"totalElements": 1,
"totalPages": 1,
"sort": {
"unsorted": true,
"sorted": false,
"empty": true
},
"first": true,
"numberOfElements": 1,
"size": 10,
"number": 0,
"empty": false
}
注:以"M_"开头的字段为主数据管理平台的系统字段。
# 根据业务主键查询数据 [5]
- 方法(Method):
GET - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/find-by-primary-key - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| withSysColumn | Query | Boolean | 查询结果是否包含系统字段 |
| version | Query | Integer | 数据版本 |
| state | Query | String | 数据状态 |
业务主键使用查询参数(Query)进行传递
- 响应报文示例:
[
{
"M_ID": "f851441c-f0fa-49f7-92fb-97c0436d8b7c",
"M_DATA_UID": "c1ab257e-fb42-4086-955b-cb3f779acf53",
"M_DATA_VERSION": 1,
"M_DATA_STATE": 0,
"M_DATA_FROM": "mdm::manual",
"M_SECURITY_LEVEL": 4,
"M_CREATED_AT": "2025-06-25 10:37:15",
"M_CREATED_BY": "admin",
"M_LAST_MODIFIED_AT": "2025-06-25 10:37:15",
"M_LAST_MODIFIED_BY": "admin",
"org_code": "shanghai",
"org_name": "上海总公司",
"principal": "张三"
}
]
注:以"M_"开头的字段为主数据管理平台的系统字段。
# 根据UID查询数据 [6]
- 方法(Method):
GET - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/{uid}/versions - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| uid | Path | String | 数据系统标识 |
| withSysColumn | Query | Boolean | 查询结果是否包含系统字段 |
| version | Query | Integer | 数据版本 |
| state | Query | String | 数据状态 |
响应报文示例:
# 插入(新建)数据 [7]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/insert - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| data | Body | Map<String, Object> | 业务数据 |
- 请求报文参考示例:(数据字段请使用数据模型定义的字段)
{
"org_code": "shanghai",
"org_name": "上海总公司",
"principal": "张三",
"_M_REF_DATA_MAP": { // 从(子)模型数据,固定写法
"MDM_EMP": [ // 从(子)模型编码
{
"emp_code": "lisi",
"emp_name": "李四",
"position": "研发",
"email": "lisi@primeton.com"
}
]
}
}
// MDM7.3支持新的从模型报文结构(省掉`_M_REF_DATA_MAP: {...}`这一层)
{
"org_code": "shanghai",
"org_name": "上海总公司",
"principal": "张三",
"MDM_EMP": [ // 从(子)模型编码
{
"emp_code": "lisi",
"emp_name": "李四",
"position": "研发",
"email": "lisi@primeton.com"
}
]
}
- 响应报文示例:
bf8da0fc-7cbf-4e29-9efe-e31bf786847d // 数据ID
# 插入(新建)并发布数据 [8]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/insert-release - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| data | Body | Map<String, Object> | 业务数据 |
请求报文体参考示例:
响应报文示例:
# 根据系统主键更新数据 [9]
- 方法(Method):
PUT - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/update/{id} - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| id | Path | String | 系统主键 |
| isAllRefData | Query | Boolean | 是否为全部从(子)模型数据 |
| data | Body | Map<String, Object> | 业务数据 |
请求报文体参考示例:
响应报文示例:
# 根据系统主键更新并发布数据 [10]
- 方法(Method):
PUT - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/update-release/{id} - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| id | Path | String | 系统主键 |
| isAllRefData | Query | Boolean | 是否为全部从模型数据 |
| data | Body | Map<String, Object> | 业务数据 |
请求报文体参考示例:
响应报文示例:
# 根据业务主键更新数据 [11]
- 方法(Method):
PUT - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/update-by-primary-key - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| isAllRefData | Query | Boolean | 是否为全部从模型数据 |
| data | Body | Map<String, Object> | 业务数据 |
请求报文体参考示例:
参考插入(新建)数据 [7](报文体中必须携带业务主键数据)
响应报文示例:
# 根据业务主键更新并发布数据 [12]
- 方法(Method):
PUT - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/update-release-by-primary-key - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| isAllRefData | Query | Boolean | 是否为全部从模型数据 |
| data | Body | Map<String, Object> | 业务数据 |
请求报文体参考示例:
参考插入(新建)数据 [7](报文体中必须携带业务主键数据)
响应报文示例:
# 根据系统主键删除数据 [13]
- 方法(Method):
DELETE - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/delete/{id} - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| id | Path | String | 系统主键 |
响应报文示例:
无
# 根据业务主键删除数据 [14]
- 方法(Method):
DELETE - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/delete-by-primary-key - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
业务主键使用查询参数(Query)进行传递
响应报文示例:
无
# 根据系统主键修订(克隆)数据 [15]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/revise/{id} - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| id | Path | String | 系统主键 |
响应报文示例:
# 根据业务主键修订(克隆)数据 [16]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/revise-by-primary-key - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| version | Query | Integer | 数据版本 |
业务主键使用查询参数(Query)进行传递
响应报文示例:
# 根据系统主键发布数据 [17]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/release/{id} - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| id | Path | String | 系统主键 |
响应报文示例:
无
# 根据业务主键发布数据 [18]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/release-by-primary-key - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
业务主键使用查询参数(Query)进行传递
响应报文示例:
无
# 根据系统主键回退历史版本数据 [19]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/rollback/{id} - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| id | Path | String | 数据ID |
| version | Query | Integer | 数据版本 |
响应报文示例:
无
# 根据业务主键回退历史版本数据 [20]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/rollback-by-primary-key - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| version | Query | Integer | 数据版本 |
业务主键使用查询参数(Query)进行传递
响应报文示例:
无
# 根据系统主键启用数据 [21]
方法(Method):
POST路径(PATH):
/api/mdm/openapi/{dataModelCode}/enable/{id}请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| id | Path | String | 数据ID |
响应报文示例:
无
# 根据业务主键启用数据 [22]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/enable-by-primary-key - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
业务主键使用查询参数(Query)进行传递
响应报文示例:
无
# 根据系统主键禁用数据 [23]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/disable/{id} - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| id | Path | String | 数据ID |
响应报文示例:
无
# 根据业务主键禁用数据 [24]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/disable-by-primary-key - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
业务主键使用查询参数(Query)进行传递
响应报文示例:
无
# 根据系统主键废弃数据 [25]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/deprecate/{id} - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
| id | Path | String | 数据ID |
响应报文示例:
无
# 根据业务主键废弃数据 [26]
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi/{dataModelCode}/deprecate-by-primary-key - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Path | String | 数据模型编码 |
业务主键使用查询参数(Query)进行传递
响应报文示例:
无
# 统一接口调用(Route|GET)
- 方法(Method):
GET - 路径(PATH):
/api/mdm/openapi - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Query | String | 数据模型编码 |
| action | Query | Integer | 目标接口Route,即接口名后面[]中的数字 |
| body | Query | String | 请求参数 |
GET方式查询就是把POST方式的请求Body进行URI编码后转成查询参数(body)方式传递。
目标接口参数传递方式:
# 统一接口调用(Route|POST)
- 方法(Method):
POST - 路径(PATH):
/api/mdm/openapi - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| dataModelCode | Query | String | 数据模型编码 |
| action | Query | Integer | 目标接口Route,即接口名后面[]中的数字 |
| body | Body | Byte[] | 请求参数 |
目标接口参数传递方式:
目标接口
Path位置参数都以查询参数Query方式进行传递,其他位置传参方式跟目标接口一致。
# 数据推送APIs
三方系统集成主数据管理平台时,如果通过webhook方式订阅主数据,则需要按下面的规范实现其中一种适配方式。
# Http
# 接收主数据管理平台数据推送API
- 方法(Method):
POST - 路径(PATH):三方系统自定义,例如
/api/mdm/hook - 请求参数:
| 参数 | 位置 | 类型 | 描述 |
|---|---|---|---|
| model | Query | String | 必填参数,数据模型编码 |
| dict | Query | Boolean | 可选参数,是否是字典,默认不是字典 |
请求报文结构参考:(以M_开头为主数据管理平台的系统字段)
[
{
"nicheng":"a",
"M_SECURITY_LEVEL":4,
"code":[//主模型关联组合模型,组合模型以数组形式返回具体数据
{
"M_SECURITY_LEVEL":4,
"code":"zuhe",
"address":"组合起来",
"M_MODEL_VERSION":1,
"M_CREATED_AT":1704266388000,
"M_ID":"0f8f95be-573b-4361-aa6f-ac0a3b363062",
"M_DATA_VERSION":1,
"M_DATA_STATE":0,
"M_DATA_UID":"4de78724-9ded-4654-818b-ab0a49691a64",
"M_LAST_MODIFIED_AT":1704266388000,
"M_CREATED_BY":"jianggl",
"M_CREATED_DEPT":null,
"M_DATA_FROM":"mdm::refdata",
"M_LAST_MODIFIED_BY":"jianggl",
"M_MODEL_ID":"b400c4b9-ee46-413f-92f6-6bd05ea9ae82"
}
],
"address":"jiangsu",
"M_MODEL_VERSION":3,
"M_CREATED_AT":1704266388000,
"address__ref":"江苏省",//关联字典显示的名称
"M_ID":"3e0470e2-64ed-4adb-bca3-8989b8b2177b",
"M_DATA_VERSION":1,
"__nichengObject":{//关联模型的整个对象
"name":"刘德华",
"id":"a",
"banji":"三年级"
},
"nicheng__ref":"刘德华",//关联模型显示名称
"M_DATA_STATE":0,
"M_DATA_UID":"f78adbd1-3b51-451b-a3f6-3d1490f0cfc8",
"name":"小刚",
"M_LAST_MODIFIED_AT":1704266388000,
"M_CREATED_BY":"jianggl",
"M_CREATED_DEPT":null,
"M_DATA_FROM":"mdm::manual",
"M_LAST_MODIFIED_BY":"jianggl",
"M_MODEL_ID":"2748e7c1-e1ce-4672-bb21-41026b7af161",
"__addressObject":{//关联字典的对象
"ID":"4fcbcc81-fb40-4518-8000-d834e38051eb",
"code":"jiangsu",
"name":"江苏省"
}
}
]
【说明】
推送的数据报文内容是JSON格式,包括系统字段(M_开头)和用户定义的模型字段(已发布),如果存在引用字段(引用字典或普通模型)可能会存在xxx__ref、__xxxObject字段值,xxx为具体关联的字段编码,用户可以根据需要使用或忽略(可以单独查询字典数据),
如果存在引用组合模型的字段,则其值为一个对象数据,如上面例子中的课程code(每一个元素的字段中也包含系统字段,因为系统字段较多示例中没添加)。
对于http推送方式,在设置推送数据限制为1条情况下默认payload是JSON Array格式,
允许在订阅者请求头里配置扩展属性EXTRA_PAYLOAD_JSON_ARRAY: false 改成单条数据格式 [{...},{...}, ...] => {...}。
字典推送报文参考:
[
{
"code": "004",
"name": "阿富汗",
"iso_number": "ISO 3166-2:AF",
"en_name": "Afghanistan",
"__event__": {
"type": "ADD",
"time": 1624603828956
}
},
{
"code": "010",
"name": "南极洲",
"iso_number": "ISO 3166-2:AQ",
"en_name": "Antarctica",
"__event__": {
"type": "ADD",
"time": 1624603828956
}
}
]
【说明】
__event__为事件相关数据,事件类型type有三个枚举值ADD MODIFIED DELETED。
下游系统接受数据成功,响应报文按Http订阅者配置验证模式,如果使用默认值则根据配置文件application-mdm.properties里校验模式决定:
#
# Validate http/https response global-settings, default: false (active while none custom settings in http-subscriber)
#
mdm.push.http.validate-response-body.enabled=true
mdm.push.http.validate-response-body.property=code
mdm.push.http.validate-response-body.pattern=200
# if multi-success-codes, e.g.
#mdm.push.http.validate-response-body.pattern=200;204
# not equals, e.g.
#mdm.push.http.validate-response-body.pattern=!500
# not in, e.g.
#mdm.push.http.validate-response-body.pattern=!401;403;404;500
# use expression (suffix: `regex: `)
#mdm.push.http.validate-response-body.pattern=regex: {COPY_YOUR_REGEX_TO_HERE}
e.g. 以上配置,对应返回格式:
{
"code": "200",
"message": "OK"
}
# 系统健康检查API
- 方法(Method):
GET - 路径(PATH):三方系统自定义,例如
/api/mdm/ping - 返回状态码
200即表示三方系统服务正常
# WebService
# 接收主数据管理平台数据推送的WebService方法
- 命名空间
namespace, 接收推送的方法名method三方系统自定义,例如hook - 方法定义以下两个参数,三方系统根据推送内容实现自己的业务逻辑
| 参数 | 类型 | 描述 |
|---|---|---|
| arg0 (model) | String | 数据模型编码 |
| arg1 (message) | String | 推送数据记录JSON内容,参考Http方式一节中的报文格式 |
| arg2 (dict) | Boolean | 是否是字典 |
Example:
package com.mdm.data.webhook;
import javax.jws.WebMethod;
import javax.jws.WebService;
import javax.jws.soap.SOAPBinding;
@WebService
@SOAPBinding(style = SOAPBinding.Style.RPC)
public class MdmDataModelWebhook {
@WebMethod
public String hook(String model, String message, boolean dict) {
// TODO your work
System.out.println("Receive a data model: " + model + " message:\n" + message);
return "OK";
}
@WebMethod
public String ping() {
return "OK";
}
}
# 系统健康检查方法
提供一个无参数的ws方法,命名空间与前者一致。
# Kafka
# 接收主数据管理平台数据推送API
配置说明:
| 参数 | 说明 | 示例 |
|---|---|---|
| 服务地址 | broker,可配置多个,用,分隔 | localhost:9092,localhost:9093 |
| 主题 | 服务端topic | test |
| 配置参数 | kafka服务端可选的配置参数,如retries,key,Partitions等 | retries:2, key:2 |
# 扩展推送实现
实现接口com.primeton.mdm.management.spi.MDMDataPushHandler 注册为 Spring Bean,把实现代码编译成JAR放入MDM程序${MDM_HOME}/lib/中即可。
如果需要覆写http, webservice实现,则调整实现类的优先级即可(覆写int getOrder(),数值越小优先级越大,默认值100)
如果扩展新的推送API类型实现,【我的账户头像】-> 【管理平台】 -> 【系统配置】 -> 【业务字典】 查找mdm-subscriber-adapter并添加类型,如kafka,这样再新增订阅者就可以选择这个新增的类型。
package com.primeton.mdm.management.spi.impl;
import com.primeton.mdm.management.model.MDMSubscriber;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.stereotype.Component;
@Component
public class KafkaDataPushHandler implements MDMDataPushHandler<KafkaSubscriber> {
int getOrder() {
return 100;
}
@Override
public String type() {
return "kafka"; // http, webservice, ...
}
@Override
public void send(KafkaSubscriber subscriber, String model, List<Map<String, Object>> data, boolean dict) {
String serverUrl = subscriber.getServerUrl();
Properties extProps = subscriber.getExtProps();
// e.g.
String user = extProps.getProperty("user", "guest");
String password = extProps.getProperty("password", "123456");
// TODO
}
}
普通订阅者扩展代码参考:(前端不做扩展,配置参数使用Key-Value方式)
package com.primeton.mdm.management.spi.push.impl;
import com.primeton.mdm.commons.util.MDMJSONUtils;
import com.primeton.mdm.management.spi.push.GeneralSubscriber;
import com.primeton.mdm.management.spi.push.MDMDataPushEncoders;
import com.primeton.mdm.management.spi.push.MDMDataPushHandler;
import com.primeton.mdm.management.spi.push.Subscriber;
import org.apache.commons.io.FileUtils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.stereotype.Component;
import java.io.File;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import java.util.Properties;
import static com.primeton.mdm.commons.util.MDMJSONUtils.toWebMvcJsonBytes;
/**
* 通用类型订阅者扩展示例:测试环境验证扩展性 —— 主要是用来验证前端web-ui是否有问题
*/
@ConditionalOnProperty(value = "mdm.push.example.enabled", havingValue = "true")
@Component
public class MDMExampleDataPushHandler implements MDMDataPushHandler<GeneralSubscriber> {
private static final String FILE_PATH = "/tmp/mdm-example-handler-out.txt";
@Override
public String type() {
return "example";
}
@Override
public void send(GeneralSubscriber subscriber, String model, List<Map<String, Object>> data, boolean dict) {
Properties properties = subscriber.getExtProps();
String filePath = null == properties ? FILE_PATH : properties.getProperty("filePath", FILE_PATH);
Subscriber.SecurityEncrypt security = subscriber.getSecurityEncrypt();
final String encoder = Optional.ofNullable(security).map(Subscriber.SecurityEncrypt::getEncoder).
filter(StringUtils::isNotBlank).filter(e -> MDMDataPushEncoders.forType(e).available(security.getOptions())).
orElse(null);
final boolean encryptEnabled = null != encoder;
try {
if (encryptEnabled) { // binary data file
byte[] bytes = MDMDataPushEncoders.forType(encoder).
encode(toWebMvcJsonBytes(data), security.isGzip(), security.getOptions());
// [length][data][length][data]...
byte[] length = String.valueOf(bytes.length).getBytes();
if (length.length != 10) { // append prefix 0
byte[] tmp = new byte[10];
System.arraycopy(length, 0, tmp, tmp.length - length.length, length.length);
length = tmp;
}
FileUtils.writeByteArrayToFile(new File(filePath), length, true);
FileUtils.writeByteArrayToFile(new File(filePath), bytes, true);
} else { // text file
FileUtils.write(new File(filePath), MDMJSONUtils.toWebMvcJsonText(data), StandardCharsets.UTF_8, true);
FileUtils.write(new File(filePath), "\n", StandardCharsets.UTF_8, true);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
# 字段编码——码段类型扩展SPI
码段分为有状态编码器和无状态编码器,比如序号(流水码)就是有状态编码器 -- 状态对象:计数器counter。
有状态编码器SPI: com.primeton.mdm.management.spi.code.StatelessEncoder无状态编码器SPI: com.primeton.mdm.management.spi.code.StatefulEncoder
# 有状态编码器扩展办法
# 定义编码器配置对象
@Getter
@Setter
public class SequenceNumber extends Config {
public static final String TYPE = "SEQUENCE";
private long start; // 起始值
private int step; // 步长(每次增长值)
private int length; // 码段长度限制
/**
* 其他字段值(一般情况下是枚举值不多,所选字段也不多1-2个)每组引用值独享一个计数器(隔离)。
*/
private String[] refFields;
/**
* 输出结果转成其他进制(一般是往大的转,16/32)
*/
private int radix = 10;
@Override
public final String getType() {
return TYPE;
}
}
# 定义状态对象(可选)
基类状态对象`State`只有一个序列号数值(计数器),如果不满足则编写子类继承它并添加需要存储的状态信息字段(存储采用JSON序列化状态信息)。
# 编写码段编码器实现
@Component("MDMSequenceNumberEncoder")
public class SequenceNumberEncoder implements StatefulEncoder<SequenceNumber, State>, Formatter<SequenceNumber> {
@Override
public final String name() {
return SequenceNumber.TYPE;
}
@Override
public Class<SequenceNumber> type() {
return SequenceNumber.class;
}
@Override
public Supplier<State> state() {
return State::new;
}
@Override
public String generate(String model, SequenceNumber config, State state, Map<String, Object> data, StateManager stateManager) {
// 最大长度 19 应该足够用了吧
final int length = (config.getLength() > 0 && config.getLength() < 20) ? config.getLength() : (config.getLength() > 19 ? 19 : 5);
long value = (state.getValue() > 0 ? state.getValue() : config.getStart())
+ (config.getStep() > 0 ? config.getStep() : 1);
StringBuilder sb = format(config, value, length);
state.setValue(value); // save-state
if (null != stateManager) {
stateManager.save(state);
}
return format(config, sb.toString());
}
private static StringBuilder format(SequenceNumber config, long value, int length) {
StringBuilder sb = new StringBuilder();
if (config.getRadix() >= 2 && config.getRadix() <= 36 && config.getRadix() != 10) {
sb.append(Long.toString(value, config.getRadix()));
} else {
sb.append(value);
}
if (sb.length() > length) {
throw new RuntimeException("Generated code snippet exceeding the length limit. " + value + " (limit length: " + length + ")");
}
while (sb.length() < length) {
sb.insert(0, 0);
}
return sb;
}
/**
* 1) 单状态模式:编码器无需实现这个方法;<br>
* 2) 多状态模式:编码器必须实现这个方法;可以根据系统当前时间和目标数据等相关信息生成一个key值作为计数器名称方便映射一个状态对象的存取操作。<br>
*
* <br>
* 有些编码需要多组状态值来记录序列(隔离)。
* e.g. 餐厅每天订单流水号(日期流水码)需要每天从头重新编号<blockquote><pre>{DAY}{SEQ}, key=>{DAY}</pre></blockquote>
* e.g. 每个班级的学号(末尾)独立序列号<blockquote><pre>{届}{专业代号}{流水号}, key=>{届}{专业代号}</pre></blockquote>
* 如果扩展的有状态编码器存在多组状态值(对于同一个模型的某字段编码的某个码段,不同码段之间完全隔离)需要根据某条数据以及系统时间等参数生成一个<blockquote><pre>key</pre></blockquote>(length: [1~200]),
* 多次调用同一套编码规则中的码段生成了相同的key则意味着他们使用了同一个状态对象(如流水码计数器),例如日期流水码按每天(或每月)到期自动重置(重新从头计数,
* 则同一天需要生成码段的时候它们使用了同一个状态对象)。
* <br>
* 使用生成的KEY关联(映射)一个状态对象(计数器)。
*
* <blockquote><pre>
* // e.g. 学生模型: 学号|届|专业代号|班级代号|身份证号|姓名|性别|出生日期|家庭住址|电话|邮箱|备注
* // 学号编码规则: {届}{专业代号}{流水号}
* // 码段1:{届} 选择日期码(系统时间|格式化年份)或引用码(`届`)
* // 码段2:{专业代号} 选择引用码(`专业代号` -- 配置关联字典)
* // 码段3:{流水号} 流水码(有状态码段)-- 计算key所需关联字段选择`届`和`专业代号` e.g. key1=2501 => 2025届数学专业 key2=2502=>2025届化学专业
* // 编码示例:
* // [key=2501] => 2025届|数学专业
* // sno=250101 => 01|张无忌
* // sno=250102 => 02|宋青书
* // ...
* // [key=2502] => 2025届|化学专业
* // sno=250201 => 01|周芷若
* // sno=250202 => 02|赵敏敏
* // ...
* </pre></blockquote>
*
* @param config 码段配置
* @param data 目标数据(部分码段类型依赖数据部分内容)
* @return 生成一个关键字(一般是用于多组状态值情况下)相关数据拼接一个字符串作为关键字,如日期流水码则关键字为日期值。这个值用于存储和读取码段状态以支持第2+次生成
*/
@Override
public String key(SequenceNumber config, Map<String, Object> data) {
if (ArrayUtils.isEmpty(config.getRefFields())) {
return null;
}
String snippets = Arrays.stream(config.getRefFields()).sorted().map(data::get).//filter(Objects::nonNull).
map(Objects::toString).collect(Collectors.joining("-"));
return StringUtils.isNotEmpty(snippets) ? snippets : null;
}
}
# 国际化配置(可选)
/META-INF/resource/i18n/encoder/SEQUENCE.properties
en_US=sequence
zh_CN=流水码
about.en_US=TODO-INTRODUCTION
about.zh_CN=TODO-INTRODUCTION
无状态编码也适用。JAR:/META-INF/resource/i18n/encoder/{NAME}.properties
# 无状态编码器扩展办法
# 定义编码器配置对象
@Getter
@Setter
public class RandomULID extends Config {
public static final String TYPE = "ULID";
private boolean uppercase;
@Override
public final String getType() {
return TYPE;
}
}
# 编写码段编码器实现
@Component("MDMULIDEncoder")
public class ULIDEncoder implements StatelessEncoder<RandomULID>, Formatter<RandomULID> {
private static final ThreadLocal<Ulid> ctx = ThreadLocal.withInitial(UlidCreator::getUlid);
@Override
public final String name() {
return RandomULID.TYPE;
}
@Override
public Class<RandomULID> type() {
return RandomULID.class;
}
@Override
public String generate(String model, RandomULID config, Map<String, Object> data) {
Ulid ulid = ctx.get();
String uuid = ulid.toString();
ulid.increment();
return format(config, config.isUppercase() ? uuid : uuid.toLowerCase());
}
}
# 国际化配置(可选)
/META-INF/resource/i18n/encoder/ULID.properties
en_US=ULID
zh_CN=ULID
about.en_US=128 bit compatibility with UUID; 1.21e+24 unique ULIDs per millisecond; Sort in dictionary order (i.e. alphabetical order); Encode it into 26 strings in a standardized manner, instead of the 36 characters of UUID; Use Crockford's base32 for better efficiency and readability (5 bits per character); Not case sensitive; No special characters (URL safe); Monotonic sorting order (correctly detecting and processing the same milliseconds)
about.zh_CN=与UUID的128位兼容性;每毫秒1.21e + 24个唯一ULID;按字典顺序(也就是字母顺序)排序;规范地编码为26个字符串,而不是UUID的36个字符;使用Crockford的base32获得更好的效率和可读性(每个字符5位);不区分大小写;没有特殊字符(URL安全);单调排序顺序(正确检测并处理相同的毫秒)